
Actas del Congreso Nacional de
Tecnología Aplicada a Ciencias
de la Salud

Actas del Congreso Nacional de Tecnología Aplicada a Ciencias de la Salud Vol. 2, 2019
El dolor es una experiencia sensorial desagradable que está presente en la mayoría de las enfermedades. Su oportuna detección es importante para ayudar en el tratamiento del paciente. Debido a lo anterior el objetivo del presente trabajo es realizar un sistema para el reconocimiento automático del dolor usando expresiones faciales, el sistema utiliza detección del rostro y la extracción de características locales de las imágenes de personas con dolor y diferentes clasificadores para la predicción. Los experimentos fueron realizados con la base de datos Painful UNBC-McMaster obteniendo resultados de hasta un 81% de exactitud en la clasificación.
Palabras clave: Visión por computadora, reconocimiento del dolor, aprendizaje de maquina
Pain is an unpleasant sensory experience that is present in most diseases. The detection of this topic is important for the treatment of the patient. The objective of the present work was the development of a system for automatic pain recognition. The system uses face detection and feature extraction in images of people with pain and different classifiers for prediction. In the experiments with UNBC-McMaster database the results of up to 81% accuracy in the classification.
Key words: Computer vision, pain recognition, machine learning
El dolor es un síntoma que se presenta en la mayoría de las enfermedades. Para su diagnóstico y medición se utilizan informes subjetivos que se conforman de dos partes: el autoinforme del paciente, el cual está basado en escalas ya establecidas, y en la evaluación del médico, considerando la observación de los signos vitales, expresión corporal del paciente, entre otros. Dichos informes subjetivos enfrentan varias limitaciones, por ejemplo, que la parte del autoinforme no se puede realizar en pacientes con ciertas alteraciones neurológicas como la demencia, cuando se tienen estados transitorios de conciencia o en pacientes que requieren asistencia respiratoria, entre otros. Sin embargo, es importante detectar el dolor y el grado del mismo para poder tratar al paciente apropiadamente [1].
Existen diferentes trabajos que abordan la detección del dolor, principalmente por medio del reconocimiento del mismo en el rostro; algunos de estos solo detectan si el dolor está presente o ausente [2,3], en otros se mide la intensidad de dolor en la que se encuentra la persona [4,5,9], para realizar la detección ya sea de dolor o la intensidad de este se utilizan métodos para la extracción de características en las imágenes algunos de estos métodos son patrones locales [6,7], puntos de referencia AAM [3,5,8], histogramas de gradientes HOG [10] que son útiles para la extracción de características en imágenes de rostros.
En la mayoría de los trabajos el reconocimiento facial se basa en el Sistema de Codificación de la Acción Facial (FACS- por sus siglas en inglés de Facial Action Coding System), que fue desarrollado por el Dr. Paul Ekman y el Dr. Wallace V. Friesen. El FACS es un sistema descriptivo basado en la anatomía de los músculos faciales, que permite identificar los cambios faciales debido a la acción de músculos individuales y en base en esto clasificar cada movimiento de los músculos del rostro en expresiones, estas se agrupan como expresiones representativas llamadas unidades de Acción (AU por sus siglas en inglés de Action Units). Algunas Unidades de Acción se pueden sumar para que la suma total represente una expresión que se pueda traducir en, por ejemplo, una emoción [11].
En el caso del dolor, este no es una emoción, sin embargo se puede medir su intensidad usando la escala PSPI (por sus siglas en inglés de Prkachin Solomon Pain Index) [12], que utiliza las AU del FACS y que consiste en sumar las unidades de acción: AU4 = bajar las cejas, AU6 = elevar la mejilla, AU7 = apretar las cejas, AU9 = arrugar la nariz, AU10 = elevar el labio superior y AU43 = cerrar los ojos, para identificar las expresiones faciales que representan dolor.
Considerando las AU antes mencionadas y la ecuación (1), podemos obtener y clasificar el rango del dolor entre 0 y 16 (Tabla 1), en donde el 0 representa que no hay dolor y 16 es la intensidad más alta del mismo [11].
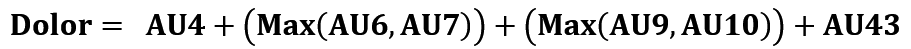
Esta escala se utiliza para clasificar las imágenes de personas que sufren dolor de hombro.
TABLA 1. Escala PSPI
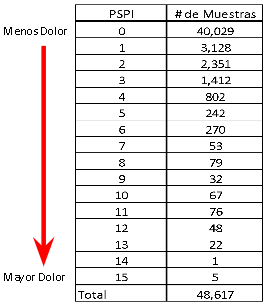
Los sistemas de reconocimiento se dividen en tres etapas: La detección, la extracción de características y la clasificación, en la Figura 1 se muestra la metodología utilizada para el desarrollo y las pruebas del sistema.
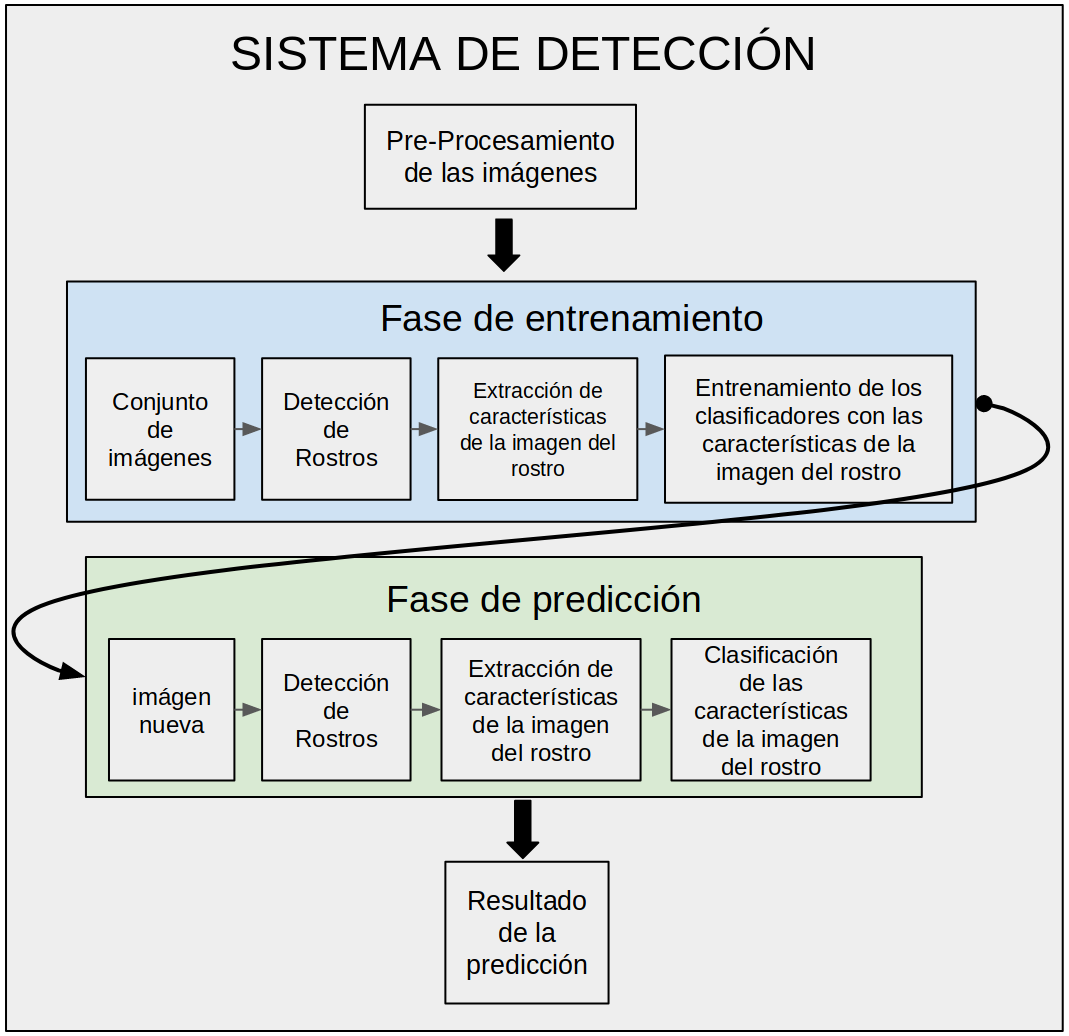
Figura 1. Metodología del sistema
En la fase de entrenamiento y en la de predicción se utilizó lo siguiente: para la detección de los rostros en las imágenes se utiliza el algoritmo de cascada de Viola-Jones, que localiza el tamaño y la posición del rostro en la imagen, después, en la extracción de las características que representan a la imagen, decidimos utilizar el método de patrones locales para la extracción del histograma global de la imagen y utilizarlo como característica. Los patrones binarios locales (LBP) actualmente se utilizan para el reconocimiento de rostros y extracción de características. En este método se trata la imagen por secciones resaltando sus características locales, dando como resultado un histograma local. Estos histogramas se concatenan para obtener un histograma global que representa las características de la imagen completa (Figura 2), algunas de las ventajas que tiene este método es que no se ve afectado por cambios de iluminación [6].

FIGURA 2. Proceso de extracción de características locales LBP
En este trabajo se entrenaron y utilizaron diferentes clasificadores: el método LBPH, el cual utiliza el algoritmo de vecino cercano, que considera la distancia mínima entre un objeto candidato y los usados en el entrenamiento para la clasificación. Además, los algoritmos basados en la máquina de soporte vectorial (SVM), siendo estos un conjunto de métodos de aprendizaje supervisado utilizados para clasificación, regresión y detección de discrepancia, los que en la clasificación se usan las versiones SVC o NuSVC, de acuerdo con el criterio de optimización preferido. La versatilidad en el tratamiento de los datos es abastecida por la función núcleo o kernel. Siendo las más consideradas la función base radial (RBF), la polinomial y la sigmoidal. Asimismo, el clasificador random forest es un algoritmo de clasificación desarrollado por Leo Breiman, el cual utiliza un conjunto de árboles de clasificación. Cada uno de estos árboles es construido con una muestra bootstrap de los datos y en cada división del conjunto de variables candidatas es un subconjunto aleatorio de las variables originales. Random forest utiliza bagging para la clasificación y selección de variables aleatorias para construir los árboles, cada árbol lo crece al máximo, por lo tanto, se obtienen árboles con bajo sesgo, pero alta varianza, por lo que se aplica el bagging para clasificar, resultando en baja correlación de los árboles individuales.
Se usó la base de datos de UNBC-McMaster Shoulder Pain Expression Archive, la cual contiene videos de rostros de sujetos adultos (25 sujetos, 12 hombres y 13 mujeres) con lesiones en el hombro. Los sujetos fueron grabados durante el movimiento de sus hombros afectados y no afectados durante condiciones activas y pasivas. En la condición activa, los sujetos iniciaron la rotación del hombro por sí mismos. En la condición pasiva, un fisioterapeuta era responsable del movimiento. El video de cada prueba fue clasificado por un codificador certificado por FACS, para extraer las unidades de acción en cada uno de los segmentos de video [11]. La clasificación es en unidades de acción, y en la escala PSPI.
Para utilizar la base de datos se tuvo que considerar primero el desbalance de la misma, debido a la gran diferencia en cantidad de imágenes en cada una de las 16 clases (de la 0 a la 15 de la escala PSPI). Mientras que la clase 0 tenía alrededor de 40000 imágenes la clase 14 solo contaba con una imagen. Para poder utilizar la base de datos se procedió a buscar la forma para que la base de datos estuviera distribuida de mejor manera para el entrenamiento de los modelos y obtener mejores resultados en su clasificación.
Se crearon diferentes modelos con diferentes cantidades de imágenes, para el primer modelo se observó la cantidad de imágenes en la base de datos de cada clase originalmente (Fig. 3) y se crearon modelos con la menor cantidad de imágenes posibles de cada clase para el entrenamiento, debido a que la clase 14 solo tenía una imagen se pasó a la clase con menor cantidad después de esta que fue la clase 15 con 5 imágenes, con base en esto se tomaron 4 imágenes por clase para entrenar el modelo. Otra forma de distribución fue separar las imágenes en la cantidad máxima de imágenes posible dejando una menor cantidad para las pruebas.
Debido a que las distribuciones de las imágenes anteriores no resultaron en un buen modelo se realizó la rotación y escalamiento en las clases con menor cantidad de imágenes (de las clases 5-15) en ángulos de -30 a 30 grados para lograr una cantidad mayor de imágenes y lograr un balanceo en la cantidad de las imágenes de cada clase, con la nueva cantidad de imágenes se crearon modelos con cantidades similares de imágenes por clase para crear diferentes modelos.
Para el primer modelo se formaron 4 grupos en donde cada grupo representa un nivel en la intensidad de dolor clase 0 (Sin dolor), las clases 1, 2, 3 y 4 (Incomodidad o dolor en baja intensidad) en el siguiente grupo, las clases 5,6,7,8 y 9 (Con dolor moderado o nivel medio de dolor) en otro y por último las clases 10,11,12,13,14,15 y 16 (Con dolor intenso o nivel alto de dolor).
Otro modelo considerado se construyó en base a [13], en él se agrupan las clases originales en cuatro grupos de la siguiente manera: las clases 0, 1, 2 y 3 quedan cada una como un grupo mientras que las clases 4 y 5 se agrupan en otro y por último las clases de las 6-16 corresponden a otro grupo.
Después de evaluar diferentes distribuciones se optó por trabajar con un modelo de cinco clases que se presenta en la Tabla 2.
TABLA 2. Escala propuesta para clasificación
| MODELO POR AGRUPAMIENTO (6 GRUPOS) | ||
|---|---|---|
| CLASE | # DE MUESTRAS PARA ENTRENAMIENTO | # DE MUESTRAS PARA PRUEBA |
| 0 | 200 | 225 |
| 1 | 196 | 206 |
| 2 | 206 | 211 |
| 3 | 205 | 193 |
| 4 | 198 | 257 |
| 5 | 219 | 474 |
Para la parte experimental se distribuyeron los datos en 6 clases (Tabla 2) para lo cual se contó con 1224 imágenes de entrenamiento y 1566 imágenes de prueba, el modelo LBP se creó considerando una malla de 8x8, con radio =1 y vecindad de 8 con lo que se obtiene como representación un histograma global de 16384 características por imagen.
Tomando los histogramas globales como características se entrenaron clasificadores basados en algoritmos vecino cercano, SVM y Random Forest.
Los resultados obtenidos aplicando diferentes algoritmos de reconocimiento a los datos basados en este modelo se presentan en la Tabla 3 y en la Figura 3.
De la Tabla 3 se observa que los mejores resultados se obtuvieron con el clasificador de distancia mínima entre las características extraídas usando LPBH. Los siguientes clasificadores presentan un comportamiento similar. De la Figura 3 se nota que también en las matrices de confusión se presenta un comportamiento similar, con los mejores resultados para las clases 0 (85%) y 5 (95%).
TABLA 3. Resultados obtenidos en clasificación
| ALGORITMO DE RECONOCIMIENTO | RESULTADOS OBTENIDOS (% DE EXACTITUD) |
|---|---|
| LBPH[14] | 81.22 |
| SVM(RBF) | 75.98 |
| SVM(SIG) | 75.86 |
| SVM(POLY 3ER GRADO) | 76.05 |
| SVM(POLY 2DO GRADO) | 75.98 |
| RANDOM FOREST | 77.33 |
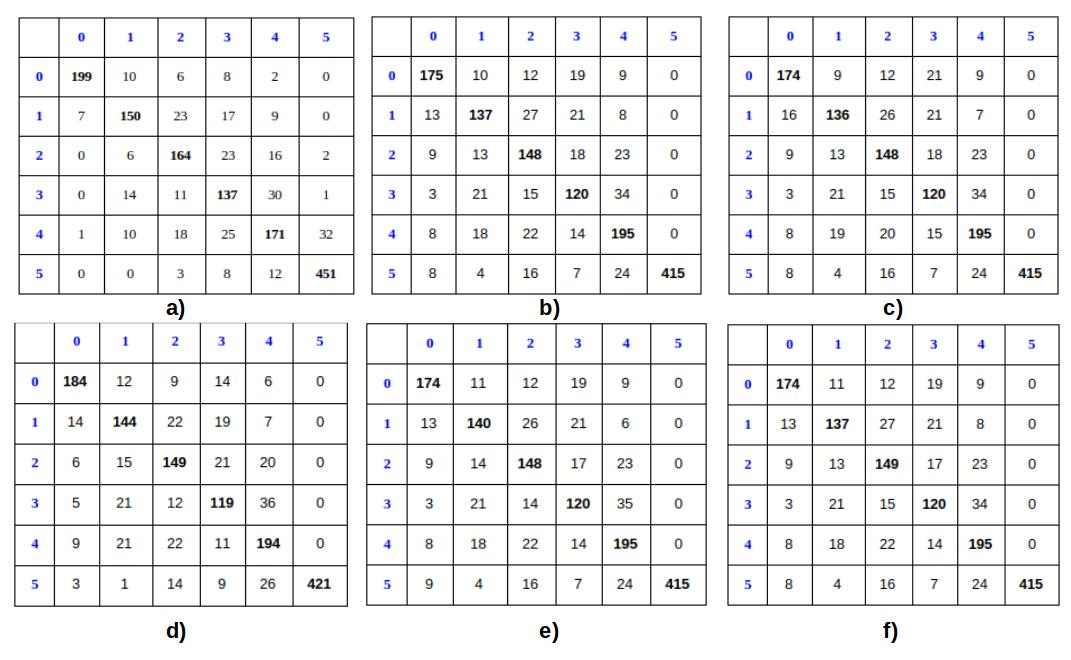
FIGURA 3. Matriz de confusión de los resultados obtenidos usando: a) LBPH b) SVM-Kernel RBF c) SVM-Kernel Sigmoidal d) SVM-Kernel Polinomial grado 2 e) SVM-Kernel Polinomial grado 3 f) Random Forest
Se presenta un sistema para el reconocimiento automático del dolor usando expresiones faciales. El sistema se basa en extraer características locales de imágenes de rostros de personas con dolor de hombro. Se realizaron experimentos con la base de datos UNBC-McMaster obteniendo resultados con hasta un 81% de exactitud en la clasificación.
Los autores agradecen a las Universidades McMaster University y University of Northern British Columbia por permitir el uso de los datos PAINFUL, Shoulder Pain Expression Archive Database.
L. Aguillón fue financiada por CONACyT.